
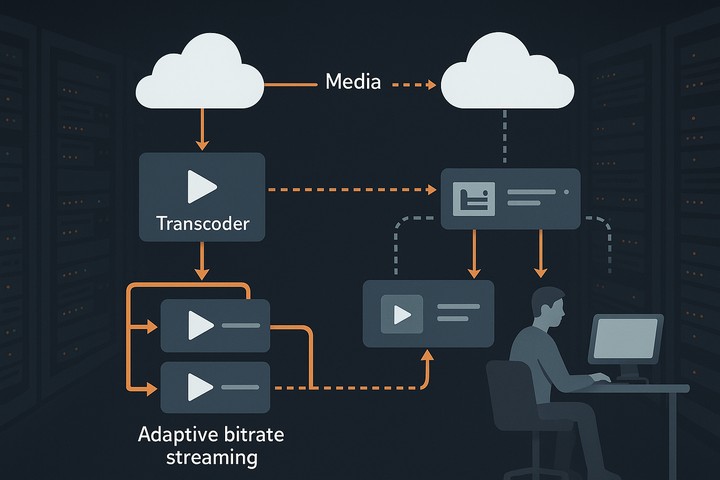
Облачные микросервисы для медиа дают способ держать поток под контролем при росте аудитории, усложнении контента и жёстких требованиях к задержке. Монолитные схемы больше не выдерживают темпа: любая ошибка тянет за собой сбой всего эфира. Переход на независимые службы с чёткими границами ответственности решает эту проблему. Архитектура становится гибкой, предсказуемой и управляемой.
Ценность подхода проявляется в каждодневной эксплуатации. Распределённый транскодер превращает один поток в несколько уровней качества, адаптивный стриминг подстраивает выдачу под сеть зрителя, сеть доставки снижает нагрузку на центральные узлы. Управление сервисами ускоряет обновления, а контроль качества обеспечивает стабильность воспроизведения.
Что такое облачные микросервисы для медиа на практике
Медиапоток проходит через цепочку автономных служб. Узлы обработки принимают вход, очередь задач распределяет работу, оркестратор контейнеров регулирует количество копий. Интерфейс взаимодействия между службами минимален: только формат данных, статусы и правила повторов. Низкая связность упрощает обновления и замену компонентов.
В монолитной схеме одна медленная операция задерживает остальные. В микросервисной архитектуре упаковка сегментов не мешает кодированию видео, а контроль качества не блокирует распределение потока. При росте трафика масштабируются только перегруженные роли, что повышает эффективность и снижает расходы.
Устойчивость достигается дисциплиной. Каждое действие идемпотентно, каждое сообщение имеет идентификатор, каждое состояние записывается в журнал заданий. При сбое повтор операции не создаёт дубликаты, а ограничение очереди защищает узлы от перегрузки.
Распределённый транскодер — сердце системы
Транскодер разделён на функциональные службы: видеодекодер потоков, препроцессор кадров, кодировщик профилей, упаковщик сегментов, валидатор параметров. Такая структура облегчает масштабирование. При росте входящих сигналов расширяется только парк кодировочных узлов, а упаковка фрагментов остаётся стабильной.
Для прямых трансляций важнее ритм, чем пиковая скорость. Стабильная задержка ценнее мгновенной производительности. Поэтому используются буферы выравнивания, а планировщик очередей дозирует нагрузку. Метрики задержки снимаются на каждом этапе — декодирование кадров, кодирование профилей, упаковка сегментов, публикация плейлиста.
Качество держится на синхронизации. Метки времени проходят все стадии, GOP-структура согласуется с длиной сегмента, сдвиг аудио контролируется валидатором. При рассинхронизации повторная упаковка исправляет расхождение без перекодирования. Для экономии мощности применяется частичный претранскодинг: востребованные уровни готовятся заранее, редкие создаются по запросу.
Механика адаптивного стриминга и мультибитрейт потока
Адаптивная доставка основана на трёх элементах: манифест вариантов, сегменты видео, список воспроизведения. Плеер выбирает нужную версию, ориентируясь на пропускную способность сети. Сервера должны поддерживать синхронность всех потоков, чтобы переход между качествами был незаметен.
Для надёжной работы плеера используют следующую типовую лестницу параметров адаптивного потока:
- Разрешение 1080p, средний битрейт 5–6 Мбит/с, GOP-длина 2 с, длина сегмента 2 с, целевой буфер 6–8 с.
- Разрешение 720p, средний битрейт 3–3.5 Мбит/с, GOP-длина 2 с, длина сегмента 2 с, целевой буфер 6–8 с.
- Разрешение 480p, средний битрейт 1.2–1.8 Мбит/с, GOP-длина 2 с, длина сегмента 2 с, целевой буфер 6–8 с.
- Разрешение 360p, средний битрейт 0.7–1.0 Мбит/с, GOP-длина 2 с, длина сегмента 2 с, целевой буфер 6–8 с.
Такой набор сохраняет качество изображения и обеспечивает устойчивость буфера. При высокой динамике сцены целесообразно повышать битрейт, не изменяя длину сегмента, чтобы не нарушать синхронизацию.
Как микросервисы взаимодействуют между собой
Коммуникация строится на очередях сообщений, каталогах задач и сервис-диспетчерах. Распределитель заданий контролирует нагрузку, ограничитель скорости предотвращает перегрузку, идемпотентная обработка исключает повторы. Каждое сообщение содержит идентификатор сегмента, метку времени и статус обработки.
Для наблюдаемости внедряются метрики производительности, трассировка запросов и журнал событий. Инженер видит время ожидания, время обработки и время публикации. При накоплении задержек перераспределение задач разгружает узлы, при росте ошибок автоматический откат восстанавливает стабильный профиль.
Система умеет обходить локальные проблемы. При всплеске трафика балансировка нагрузки направляет зрителей к ближайшим узлам, ограничение подключений защищает центральное хранилище, перераздача сегментов выравнивает кэш.
Сравнение стратегий размещения обработки
| Подход | Ключевые особенности |
| Центральная обработка | Все процессы выполняются в одном центре. Простая эксплуатация и единые профили, но высокая нагрузка на магистрали и риск узких мест в часы пик. Подходит для стабильных потоков и умеренной аудитории. |
| Распределённая обработка | Кодирование и доставка происходят ближе к зрителю. Даёт короткий путь и низкую задержку, но требует больше ролей и усложняет поддержку. Оптимальна для живых событий и широкой географии. |
Хранение, кэширование, доставка
Хранилища делятся по степени востребованности. Горячее хранилище содержит активные сегменты видео, тёплое — недавно использованные версии, холодное — исходники. Для экономии пространства заранее готовится только верх лестницы, редкие уровни пересчитываются по запросу.
Доставка обеспечивается через сеть доставки с локальными узлами. Кэш популярных сегментов снижает нагрузку на центр, а управление сроком жизни предотвращает переполнение дисков. При изменении профиля инвалидация плейлистов проходит синхронно, обновление варианта не вызывает пауз у зрителя.
Для планирования используется простая модель. Суммарный битрейт вариантов умножается на число одновременных зрителей — это целевая полоса. Задержка равна двум длинам сегмента плюс сетевой запас. Резерв мощности задаётся процентом от средней нагрузки, что позволяет масштабироваться без ручного вмешательства.
Надёжность, качество, эксплуатация
Главное правило — сбой не должен распространяться. Для этого применяются повтор задач, разделение очередей и ограничение ретраев. При ошибке в фрагменте повторная упаковка восстанавливает поток. При отказе узла переназначение сегмента переводит задачу к соседу.
Контроль качества ведётся по трём направлениям. Первое — метрики задержки и ошибки обработки. Второе — показатели буфера у зрителя, собираемые плеером. Третье — профиль битрейта на выходе транскодера. Совмещение трёх каналов даёт полное представление о состоянии системы.
Эксплуатация выигрывает от прозрачных интерфейсов. Версионирование контрактов позволяет обновлять службы независимо. Синий-зелёный раскат снижает риск деградаций. Анализ журнала событий помогает выявлять скрытые зависимости: рост ошибок после пересборки кодека, увеличение задержки после изменения длительности фрагмента.
Почему микросервисы стали стандартом
Практический смысл подхода прост: распределённый транскодер обеспечивает гибкость, адаптивный стриминг — стабильность для зрителя, сеть доставки — предсказуемую отдачу, управление сервисами — обновления без остановки, контроль качества — раннее обнаружение проблем. Разделение системы на малые роли делает её управляемой.
Когда каждая роль автономна, планирование превращается в точный расчёт. Видна потребность в мощности, понятен резерв по пику, прозрачен сценарий восстановления. Инженер получает инструмент, который переносит фокус с устранения аварий на повышение качества потока.
Именно поэтому облачные микросервисы для медиа стали стандартом. Они позволяют выдерживать рост нагрузки, удерживать задержку в пределах нормы и улучшать качество изображения без избыточных трат. Зритель получает стабильный поток, а команда — уверенность в системе.
Вопросы и ответы
Монолит работает до первого масштабирования. Как только нужно добавить поток, новый формат или дополнительный сервис — обновление превращается в риск. Микросервисы дают изоляцию и независимое обновление компонентов без остановки эфира
Да. Архитектура не зависит от поставщика. Сервисы можно развернуть в локальном дата-центре, в частном облаке или на нескольких площадках. Главное — единые стандарты взаимодействия и автоматизация развертывания.
Собирайте метрики задержки, ошибки обработки и отклонения битрейта. Совмещайте их в единой панели мониторинга. Качество держится не на одном показателе, а на совокупности трёх каналов — серверных, клиентских и контрольных измерений.
Используйте очереди сообщений с подтверждением доставки и ограничение ретраев. Повторы должны быть идемпотентными. При временных обрывах задачи автоматически переходят на соседние узлы.
Оптимум — 2 секунды. Короткие сегменты снижают задержку, но повышают нагрузку. Для низкой задержки допустимо 1 с, если система выдерживает частые запросы и сохраняет синхронизацию.